Since my master studies, I built and maintained a personal research database and interface. It is geared to support the management of the primary sources I use and to process the information that derives from them. From time to time I will make some improvements to the interface or the underlying database structure to make my life simpler when I want to extract data or to work through the analysis of some texts. Recently I have taken upon me to make two major improvements to the display which turned out to be very simple to implement.
Generation of annotations on the fly
The way the interface of the database is set up, all information about the tokens from the texts are stored in relational tables, leaving the text pristine and unannotated. The idea behind this design decision was to make it very easy to port texts from and to the cdli without hassle. The format is exactly the same so no change or conversion is needed when importing or exporting. Because of that, I used to show the vocabulary of a text in a section above the text itself, just like this:

Now if I could have the tokens with interlinks to their respective individual views outside of the text, surely I could have it on the text itself too. In order to do this, I had to tokenize the transliteration and match tokens with my pre-generated token list that shows up in the vocabulary section. It took a bit of tweaking to get to the exact same cleaning of the texts token for a perfect match. I also decided to add a tooltip with information about the lemma attached to the token so if I don’t remember what a word means or if I want to reach the lemma page from the text, I can just click on the link in the tooltip. The code for this display is a bit crude, I will probably take the time to clean it up at some point but here it is :
<div id="translit">
<?php
$lines = explode(PHP_EOL, $tablet['Tablet']['translit']); // separate the text into lines
foreach ($lines as $line){
$line = trim($line,' ');
if (is_numeric(mb_substr($line, 0, 1, 'utf-8'))){ // if the line starts with a number (= contains text to tokenize)
$rgx="/^\d+(\'*)\.\s/";
$split=preg_split($rgx, $line); //add exact line numbering to $translit and remove from the line currently being processed
preg_match($rgx, $line, $match);
$translit.=$match[0]; $line=$split[1];
$tokens = explode(" ", $line); //split into tokens
foreach ($tokens as $token){ // then treat each token
$stripped_token = str_replace(array('~','"','[', ']', '#','_'), '', $token); //clean up the tokens
$stripped_token = trim(str_replace(array('[x]'), 'x', $stripped_token));
$voc=0;
foreach ($vocab as $vocab_unit){ // roll through the vocabulary assigned to this entry and match token with token
if ($vocab_unit['Term']['term']==$stripped_token){
$ann='<div class="ttip">'; // create an annotated part of text with its tooltip
$ann.=$this->Html->link($token, array('controller' => 'terms', 'action' => 'view', $vocab_unit['Term']['id']));
$ann.='<span class="tttext">';
$ann.=$this->Html->link($vocab_unit['Word']['word'], array('controller' => 'words', 'action' => 'view', $vocab_unit['Word']['id']));
$ann.='<br />';
$ann.=$this->Html->link($vocab_unit['WordType']['word_type'], array('controller' => 'word_types', 'action' => 'view', $vocab_unit['WordType']['id']));
$ann.='<br />';
$ann.=$vocab_unit['Word']['translation'];
$ann.='<br />';
$ann.=$vocab_unit['Word']['comments'];
$ann.='<br />';
$ann.=$vocab_unit['Word']['bibliography'];
$ann.='</span></div>';
$translit.=$ann;
$translit.=" ";
$voc=1;
break;
}
}
if ($voc !=1) {
$translit.= $token." ";
}
}
}
else{
$translit.=$line;
}
translit.="<br />";
}
echo $translit;
?>
</div>
The result looks like this:

And the tooltip:

The links lead to the individual view for the token, the lemma and the word type, this last display shows a list of lemma of this type in the corpus.
Diff(erences) visualization with the most recent cdli transcription
At some point I will upload my transliterations to the cdli since in order to make it easy to computationally process the data from the text, I harmonize all readings across the corpus, readings which are based on a dozen authors and my own work. Sometimes it would be helpful to know exactly what is the difference between my transcription and the one offered in the cdli which can be modified by any cdli editor. Because we recently set up daily data dump from the cdli, I was able to set up on my own computer a daily download of the file so I can use it for comparison. First I create a shell script to grab the file and inflate it and I have this script run daily as a cron task.
cd /alty/data/cdli_data/ wget -O cdli_catalogue.csv.zip https://github.com/cdli-gh/data/raw/master/cdli_catalogue.csv.zip wget -O cdliatf_unblocked.atf.zip https://github.com/cdli-gh/data/raw/master/cdliatf_unblocked.atf.zip unzip -o '*.zip'
At all times, my folder looks like this :
From the archive, I can search for the entry I need and store it into the database. I decided to have this process run at the time when I call the view for an entry in my database. Luckily, reading the text file is very fast and it only adds about 2 seconds to loading the page which is fine for me. First I added a field to my tablet table to store the cdli atf for the entries. Then I implemented a little script that fetches the atf of the specific entry from the archive and stores it in the database. it comes right before the logic to prepare the data for display :
$tablet = $this->Tablet->find('first',array('conditions' => array('Tablet.id' => $id),'contain' => array()));
$atf_file=file_get_contents('/alty/data/cdli_data/cdliatf_unblocked.atf');
if(strpos($atf_file, $tablet['Tablet']['no_cdli'])){
preg_match('/(&'.$tablet['Tablet']['no_cdli'].'(.+?)&P)/s', $atf_file, $out);
$this->Tablet->id = $id;
$this->Tablet->set('cdli_atf','&'.$tablet['Tablet']['no_cdli'].$out[2]);
$this->Tablet->save();
}
Because I am using the CakePHP framework, it is quite easy to interact with the database. When this is ready, then I need to show both atf version on the entry view and also add the diff visualization. I decided to implement a nice php diff class that I found when we needed to show changes in version histories for the cdli. (It was implemented on the cdli by Prashant Rajput.) You can see an example here. The display code looks like this:
<div id="cdli_atf">
<?php
require_once(ROOT . DS . 'app' . DS .'Vendor' . DS . 'FineDiff' . DS . 'finediff.php');
$to_text = implode("\n", array_map('trim', explode("\n", $tablet['Tablet']['cdli_atf'])));
$from_text = implode("\n", array_map('trim', explode("\n", $tablet['Tablet']['translit'])));
$opcodes = FineDiff::getDiffOpcodes ( rtrim($from_text), rtrim($to_text), FineDiff::$wordGranularity );
$opcodes = FineDiff::renderDiffToHTMLFromOpcodes($from_text,$opcodes);
echo str_replace('\n','<br />', nl2br($opcodes));
?>
</div>
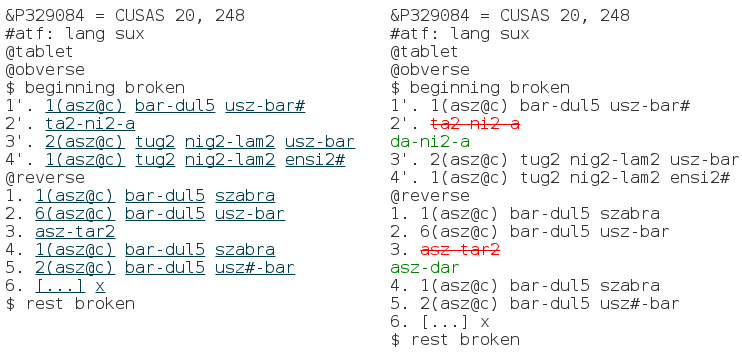
FineDiff does all the legwork and we are left to enjoy the result:
 Read More
Read More